TimeSeries Analysis – PBMC example run
Yohan Lefol
18. November 2025
Source:vignettes/TS_analysis_PBMC.Rmd
TS_analysis_PBMC.RmdTimeSeries analysis
Parameter set up
Set the below parameters for the downstream analysis
#Give names to saved object and name of results repository
name_result_folder<-'TS_results_PBMC_example/'
obj_name<-'timeSeries_obj_PBMC_example.Rdata'
#Set-up time series object parameters
diff_exp_type<-'DESeq2' #package used for DE – can also be 'limma'
p_val_filter_type<-'padj' #Either padj or pvalue, used to filter for significance
p_thresh<-0.05 #pvalue or padj value threshold for significance
l2fc_thresh<-1 #log(2)foldChange threshold for significance
name_control<-'LPS' #Name of experiment as seen in the sample file
name_experiment<-'IgM' #Name of control as seen in the sample file
graphic_vector<-c("#e31a1c","#1f78b4") #Pre-set colors for the groups
#Declare organism and load library
org_sem_sim='org.Hs.eg.db'
library('org.Hs.eg.db')## Loading required package: AnnotationDbi
#Define specimen and ontology parameters
my_ont_gpro='GO:BP'
my_ont_sem_sim='BP'
my_org_gpro='hsapiens' #Set the species for the gprofiler analysis
# The seed serves to create reproducible results with PART.
# A seed will ensure that the random components of PART clustering will be the same
# as long as the same seed is used. For more information on seeds, please consult
# this link: https://www.r-bloggers.com/2018/07/%F0%9F%8C%B1-setting-a-seed-in-r-when-using-parallel-simulation/
PART_seed=123456
PART_l2fc<-2 #log(2)foldChange threshold for PART clustering
PART_min_clust<-50 #Minimum cluster size for PART
part_bootstrap<-100 #Number of recursions, default is 100, using 10 for example
log_tp_traj<-FALSE #Defines if timepoints should be log transformed for illustration purposes
# Allows for all temporal combinations to be done instead
# of just sequential comparison. ex: do TP2vsTP1, TP3vsTP2, AND TP3vsTP1. In a normal instance
# only the first two comparison of the example would be run.
do_all_temporal_comparisons=FALSE
#Used to highlight specific genes regardless of differential gene expression significance
genes_of_interest <- c('AICDA','APOBEC3H','APOBEC3F','APOBEC3D','APOBEC3C','APOBEC3G','APOBEC3B','APOBEC3A','SMUG1','UNG','EGFR')
#The ancestors that will be queried, the ontology must be specified (BP,MF,or CC)
#Set to an empty vector c() if not required by the analysis
target_ancestors<-c('GO:0002253','GO:0019882','GO:0002404','GO:0002339','GO:0042386',
'GO:0035172','GO:0002252','GO:0006955','GO:0002520','GO:0090713',
'GO:0045321','GO:0001776','GO:0050900','GO:0031294','GO:0002262',
'GO:0002683','GO:0002684','GO:0002440','GO:0002682','GO:0002200',
'GO:0045058','GO:0002507')
ancestor_ontology<-'BP'
#Some extra set-up
name_save_obj<-paste0(name_result_folder,obj_name)#The object will be saved in result folder
#Create main directory for results, removed for vignettes
# dir.create(name_result_folder)
my_group_names<-c(name_experiment,name_control)
names(graphic_vector)<-c(name_experiment,name_control)Create TimeSeries object
Using the parameter above, generate a TimeSeries_Object and load the example data as well as the semantic similarity data
TS_object <- new('TimeSeries_Object',
group_names=my_group_names,group_colors=graphic_vector,DE_method=diff_exp_type,
DE_p_filter=p_val_filter_type,DE_p_thresh=p_thresh,DE_l2fc_thresh=l2fc_thresh,
PART_l2fc_thresh=PART_l2fc,sem_sim_org=org_sem_sim,Gpro_org=my_org_gpro)
TS_object <- TS_load_example_data(TS_object)
TS_object <- add_semantic_similarity_data(TS_object,my_ont_sem_sim,vignette_run=TRUE)Differental gene expression analysis
Loads the necessary functions to perform differential gene expression analysis If the tool used is DESeq2(Love, Huber, and Anders 2014), the data needs to be normalized using it’s method. If the tool used is limma(Smyth 2005), the normalized matrix should have been inputed, and thus no normalization is needed.
This code chunk performs both the conditional and temporal differential gene expression and saves the results within the Time Series object.
#Perform normalization if the DESeq2 tool is being used and if normalized matrix doesn't exist
if (slot(TS_object,'DE_method')=='DESeq2' & 'norm' %in% names(assays(slot(TS_object,'exp_data')))!=TRUE){
TS_object <- normalize_timeSeries_with_deseq2(time_object=TS_object)
}
#Perform conditional differential gene expression analysis
TS_object<-conditional_DE_wrapper(TS_object,vignette_run=TRUE)
#Perform temporal differential gene expression analysis
TS_object<-temporal_DE_wrapper(TS_object,do_all_combinations=do_all_temporal_comparisons,vignette_run=TRUE)PART clustering
The code chunk below prepares and initiates PART clustering(Nilsen et al. 2013). It first retrieves the number of significant genes for PART clustering in the ‘signi_genes’ variable This chunk can be quite lengthy depending on the number of genes included for clustering as well as the number of recursions set for the clustering
#Extract genes for PART clustering based on defined log(2)foldChange threshold
signi_genes<-select_genes_with_l2fc(TS_object)
#Use all samples, but implement a custom order. In this case it is reversed
samp_dta<-exp_sample_data(TS_object)
TS_groups<-slot(TS_object,'group_names')
samps_2<-samp_dta$sample[samp_dta$group==TS_groups[2]]
samps_1<-samp_dta$sample[samp_dta$group==TS_groups[1]]
#Create the matrix that will be used for PART clustering
TS_object<-prep_counts_for_PART(object=TS_object,target_genes=signi_genes,
scale=TRUE,target_samples=c(samps_2,samps_1))
#Sets a seed for reproducibility
if (is.null(PART_seed)==FALSE){
set.seed(as.character(PART_seed))
}
TS_object<-compute_PART(TS_object,part_bootstrap=part_bootstrap,part_min_clust=PART_min_clust,
custom_seed=PART_seed,dist_param="euclidean", hclust_param="average",
vignette_run=TRUE)Gprofiler analysis
The code chunk below runs a gprofiler analysis(Kolberg et al. 2020; Raudvere et al. 2019). IMPORTANT: This function requires that there be a stable internet connection lack of connection or intermittent drops in the connection will result in an error and the termination (stop) of the code chunk
If an error has occured, this code chunk can be re-run separately from the above chunks by uncommenting (removing the ‘#’ in front) the “load(‘timeseries_obj_res.Rdata’)” line.
This will load the results saved after the PART clustering code chunk
This code chunk will overwrite the saved object if it is completed. The overwritten object will then contain the gprofiler analysis results and can be used to generate plots with the downstream code chunks.
TS_object<-run_gprofiler_PART_clusters(TS_object,vignette_run = TRUE) #Run the gprofiler analysisTimeSeries analysis results
Most plots are created in SVG format for ease of editing with SVG editing software such as InkScape (open source software). Some plots are created in html format as they are interactive plots. These require a web browser to open them
To convert SVG files to PNG/JPG/PDF, this website is available: https://svgtopng.com/ HTML files can be opened and then saved as PNG (or other) using the camera icon in the top right of each respective interactive plot
TimeSeries summary of experiment
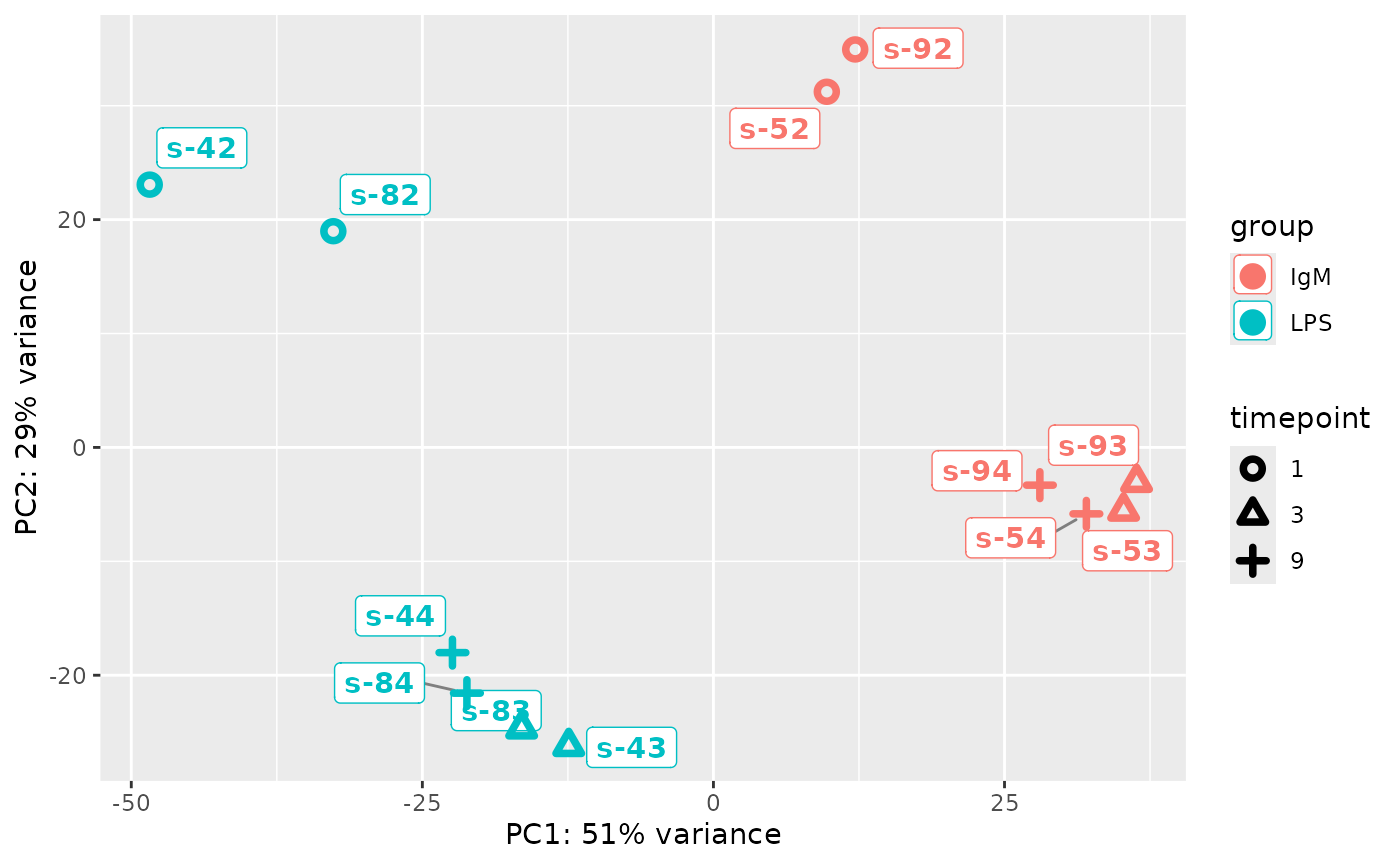
Name of groups beings compared: IgM vs LPS Number of genes analyzed: 1691
Differential expression parameters used: Method: DESeq2 P statistic filter used: padj with a 0.05 threshold Log(2)FoldChange significance threshold used: 1
PART parameters used: PART log(2)FoldChange significance threshold: 2 number of recursions: minimum cluster size: 50 distance parameter: euclidean hclust parameter: average custom seed used: 123456 PART computation time: 270.209 sec elapsed
PCA of sample data:
Differential Gene Expression results (as per plot_wrapper functions)
DEGs found per analysis:
| experiment.name | number.of.DEGs |
|---|---|
| IgM_vs_LPS_TP_1 (conditional) | 464 |
| IgM_vs_LPS_TP_3 (conditional) | 758 |
| IgM_vs_LPS_TP_9 (conditional) | 807 |
| TP_3_vs_TP_1 (temporal) | 300 |
| TP_9_vs_TP_3 (temporal) | 4 |
| total unique genes | 1308 |
Each experiment listed in the above table has separate results which can be viewed in the ‘TS_results’ folder. In the main results folder, the differential gene expression results are located in the ‘DE_results_conditional’ and ‘DE_results_temporal’ plot. Each individual experiment creates the following: DE_raw_data.csv: A csv file containing all the genes and their associated differential expression results, regardless of significance. DE_sig_data: A csv file containing only the significant differential expression results. MA_plot.png: A MA plot, these are often used to evaluate the quality of the normalization. volcano_plot.png: A volcano plot which splits significantly up-regulated and down-regulated genes as well as non-significant genes. PCA_plot: A PCA plot using only the samples implicated in the differential gene expression analysis.
The pipeline also creates two large heatmaps which summarize conditional and temporal differential expression results. The heatmaps were created using the ComplexHeatmaps package(Gu, Eils, and Schlesner 2016). These heatmaps illustrate each experiment as different columns (distinguished by color) while the rows distinguish the groups. Plotted in the heatmaps is the log transformed counts, while the log transformed log(2)fold change is seen in a histogram at the bottom of the heatmap. The number of genes in each experiment (colored columns) is indicated in the legend at the bottom of the heatmap. This heatmap is shown below. In the case of the temporal heatmap, the rows are labelled ‘experiment’ and ‘control’. The ‘experiment’ represents the time points being compared while the control represents the timepoint which the ‘experiment’ is compared against. For example, TP2_vs_TP1 would have the ‘experiment’ be TP2 and the control be TP1, while TP3_vs_TP2 would have TP3 as the ‘experiment’ and TP2 as the ‘control’. Note that TP=time point.
The conditional heatmap
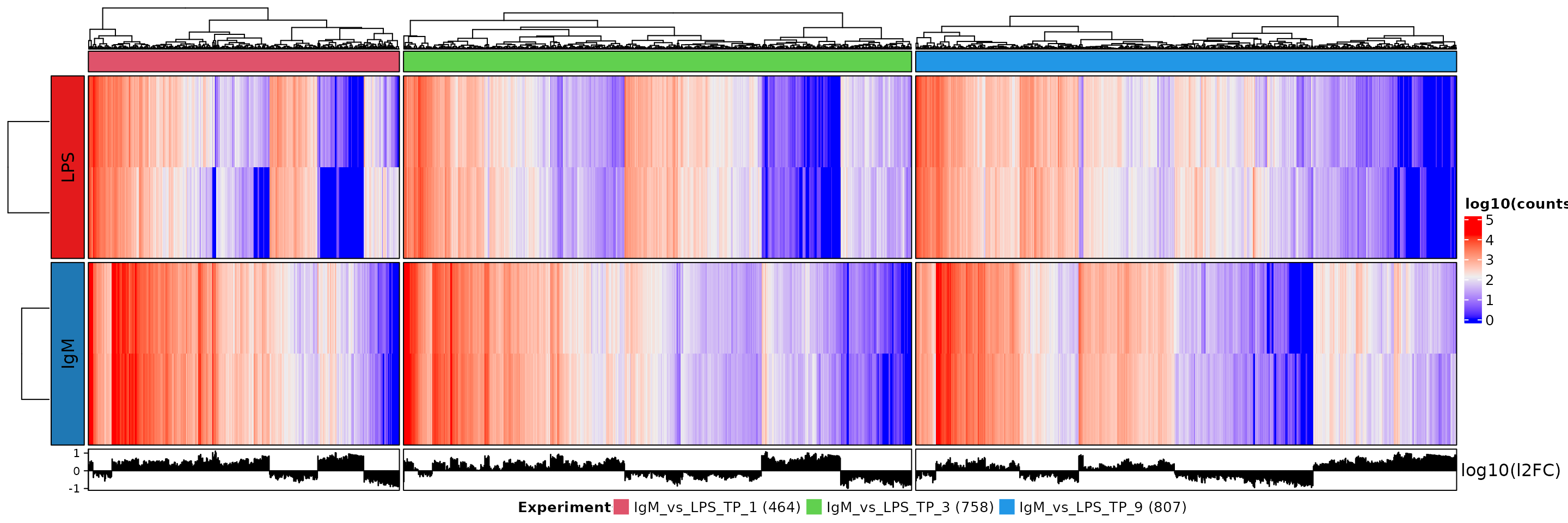 ## Genes of interest results
## Genes of interest results
 If genes of interest have been specified, the pipeline will extract the
differential gene expression results, both conditional and temporal, for
each gene requested, provided that they are found in the count matrix.
These data files, along with individual trajectory plots are stored in
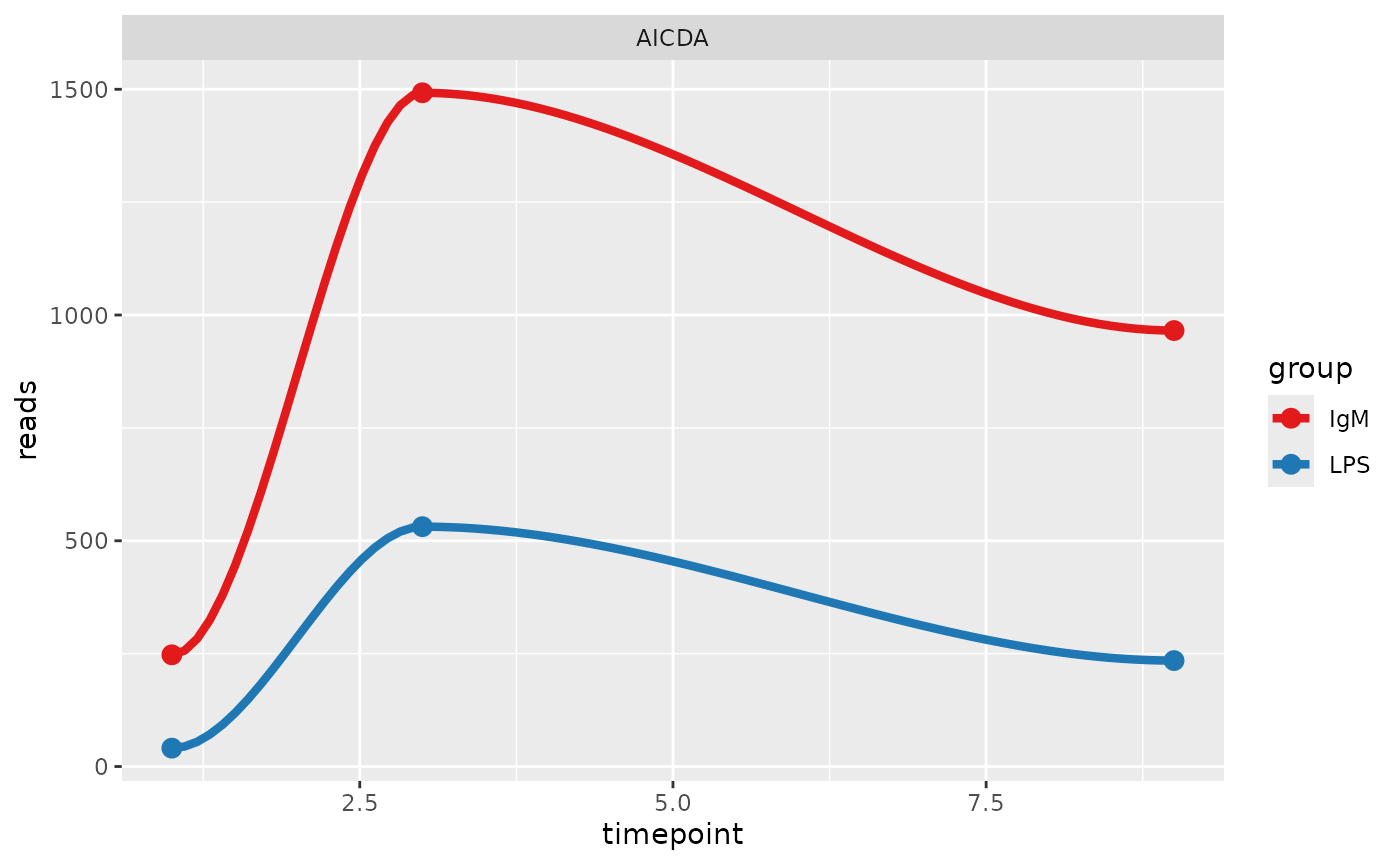
the ‘TS_results/genes_of_interest’ folder. Below the trajectory of the
most variable gene is shown. If no genes of interest were submitted, a
random gene is taken from the differential expression results.
Illustrated in the trajectory plots is the timepoints on the x axis and
the number of reads (RNAseq) or expression (microarray) on the y axis.
Note that data files and trajectory plots are created for all genes of
interest found, regardless of their significance based on the
differential gene expression analyses.
If genes of interest have been specified, the pipeline will extract the
differential gene expression results, both conditional and temporal, for
each gene requested, provided that they are found in the count matrix.
These data files, along with individual trajectory plots are stored in
the ‘TS_results/genes_of_interest’ folder. Below the trajectory of the
most variable gene is shown. If no genes of interest were submitted, a
random gene is taken from the differential expression results.
Illustrated in the trajectory plots is the timepoints on the x axis and
the number of reads (RNAseq) or expression (microarray) on the y axis.
Note that data files and trajectory plots are created for all genes of
interest found, regardless of their significance based on the
differential gene expression analyses.
Cluster results
The code chunk below create the trajectory plots for the clusters found by PART Trajectories are first calculated by calculating the mean of each gene for each time point using the available replicates. The mean value of each gene is calculated once for each group (control/experiment). Afterwards, the genes are scaled in order to be able to represent them on the same axis of values. Each gene is plotted as an individual colored line’, a mean line (gray color) is also plotted to show the overall trajectory of the cluster. These plots were inspired by (Nguyen 2021)
The log_tp_traj parameter defines if the time points should be log transformed. A log transformation of the time points is useful if the time points are not evenly sampled through time. For example, two time points at 0 and 15 minutes, with another time point at 24 hours (1440 minutes) will result in the first two time points being very compressed and possibly indistinguishable from each other.
# dir.create(paste0(name_result_folder,'PART_results')) #create the directory to store results
PART_heat<-PART_heat_map(TS_object,NULL) #Create a summary heatmap, returns plot if save location is NULL
ts_data<-calculate_cluster_traj_data(TS_object,scale_feat=TRUE) #Calculate scaled gene values for genes of clusters
mean_ts_data<-calculate_mean_cluster_traj(ts_data) #Calculate the mean scaled values for each cluster
#Function which determines the number of SVG files to plot all cluster trajectories
#Function commented out for vignettes
# wrapper_cluster_trajectory(TS_object,ts_data,mean_ts_data,log_TP=log_tp_traj,plot_name=paste0(name_result_folder,'/PART_results/Ctraj'))
#find the most variable cluster, subset necessary data and plot it on a single column
#The function will also filter for a cluster which has gprofiler results
target_clust<-find_most_variable_cluster(TS_object,mean_ts_data)
sub_ts<-ts_data[ts_data$cluster==target_clust,]
sub_mean<-mean_ts_data[mean_ts_data$cluster==target_clust,]
plt_clust<-plot_cluster_traj(object = TS_object,ts_data = sub_ts,ts_mean_data = sub_mean, num_col=1,rem_legend_axis=TRUE,log_TP=log_tp_traj)
cluster_map_sum<-t(as.data.frame(table(slot(TS_object,'PART_results')$cluster_map[,c(1)])))
row.names(cluster_map_sum)=c('Cluster name','Number of genes')
colnames(cluster_map_sum)=NULLPART result summary:
| Cluster name | C1 | C10 | C11 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 |
| Number of genes | 120 | 53 | 66 | 154 | 69 | 134 | 165 | 87 | 84 | 113 | 91 |
All cluster results are found in the ‘PART_results’ folder, within this folder you will find the following, Note that this folder exists if the a save_location is given to the function and that the function is used.:
PART_heat.svg: A svg heatmap of the PART result – detailed below. PART_heat_with_names.svg: The same plot as above but with sample and gene names included. These may not be visible depending on the number of genes included as well as the length of the sample names. PART_heat_cmap.csv: A csv file representing a ‘cluster_map’ which provides the cluster in which each gene was sorted in as well as the color (in HEX code) given to that cluster. PART_heat_data.csv: The z-score values used in the ‘PART_heat’ heatmaps. Ctraj.svg: At least one, and possibly several of these files will be in the folder. This/these SVG plots show the trajectory of each cluster individually while being split by group. Meaning the trajectory of each cluster is shown twice, once per group. Information concerning the cluster and group is shown in the title of each subplot. One example of cluster trajectory is shown below.
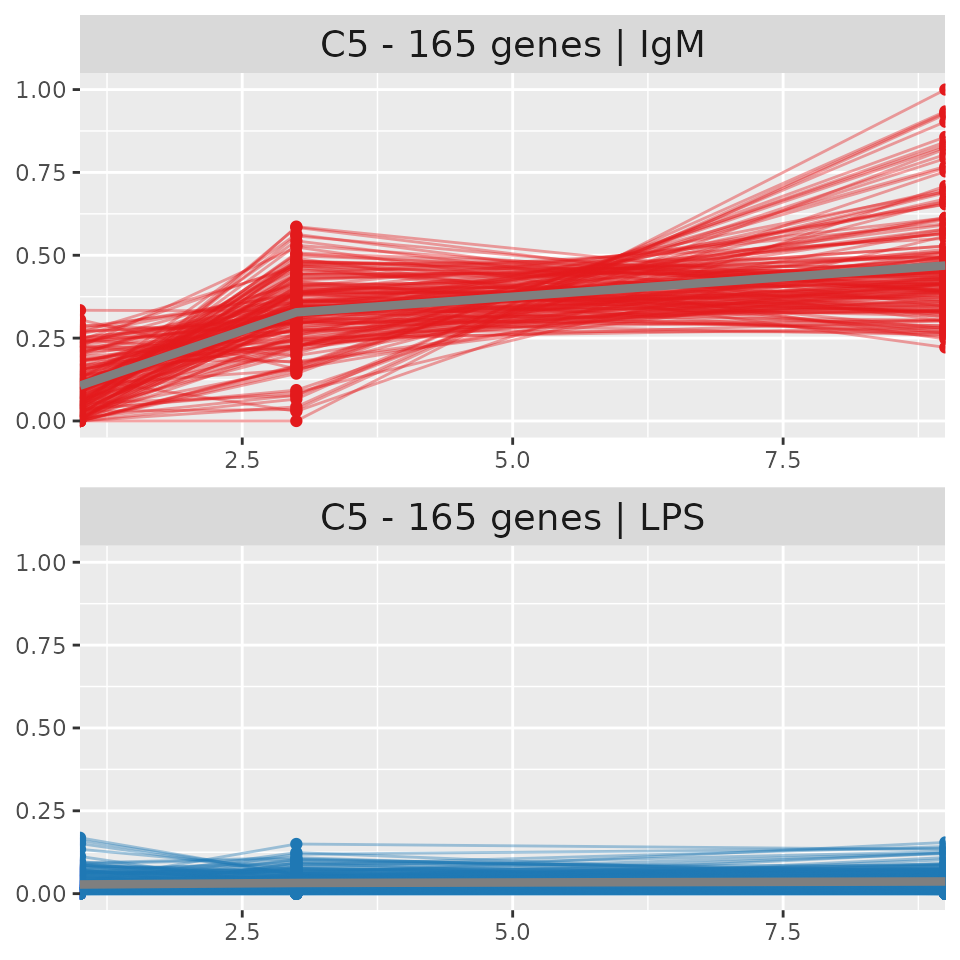
PART heatmap and cluster trajectory In this heatmap we illustrate all the genes which were submitted for PART clustering. Each gene is illustrated using a Z-score, which measures the number of standard deviations that a gene has from it’s mean. In essence it measures the variability. Clusters are shown as the colored bar on the left hand side of the plot while groups and timepoints are shown as the colored bars on the top of the heatmap. PART heatmaps were created with ComplexHeatmaps(Gu, Eils, and Schlesner 2016). The cluster trajectory of the most variable cluster (C5) is illustrated, with the trajectory of the experiment group at the top and the control group at the bottom. The x axis represents timepoints and the y axis represents the scaled mean expression of the genes. The expression of each gene is obtained by calculating the mean between all replicates for each time point in each group. The values are then scaled in order to illustrate their trajectory. The overall mean of the cluster is shown as a thicker gray line.
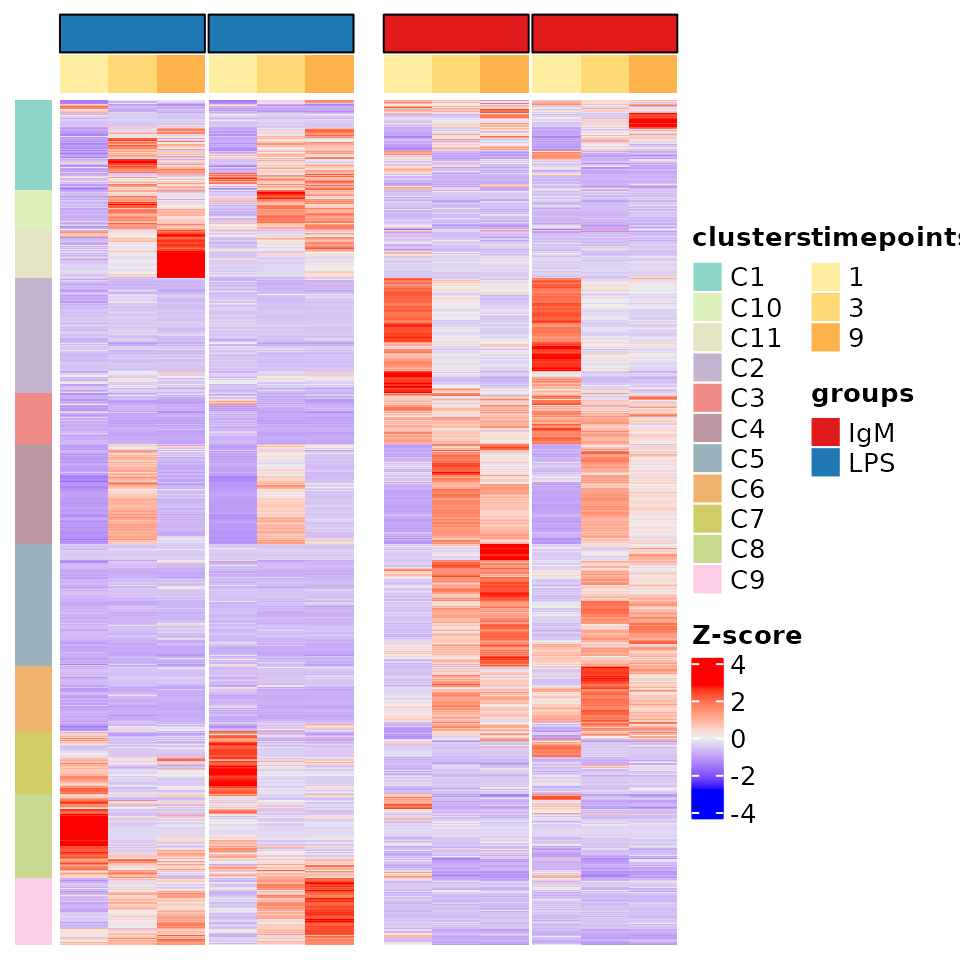
Gprofiler results – standard
The below chunk creates the gprofiler result. Some parameters relating to the species and ontology need to be defined the Multi-Dimensional Scaling (MDS) plots that will be generated by the last function of this code chunk. Both versions of the MDS plots seen below were inspired by (Brionne, Juanchich, and Hennequet-Antier 2019).
The ontology needs to be defined for the MDS plots as well. Note that MDS plots utilise the semantic similarity metric which currently only supports GO ontology (MF – MolecularFunctions, CC – Cellular Components, and BP – Biological processes). These have been defined at the start. The first function plots the standard gprofiler plots (gost plots) to the directory, and it retrieves the information of the requested ontology into the GO_clusters dataframe. This dataframe is then used with the semantic distance to create two versions of the MDS plot.
#Create standard gprofiler results
gpro_res<-gprofiler_cluster_analysis(TS_object,my_ont_gpro,save_path=NULL,
return_specific_cluster=target_clust,
return_interactive=TRUE)
GO_clusters<-gpro_res[['GO_df']]
sem_dta<-slot(TS_object,'sem_list')
#Plot and save MDS and clustered MDS
MDS_plots<-wrapper_MDS_and_MDS_clusters(GO_clusters,sem_dta,my_ont_sem_sim,target_dir=NULL,return_plot=TRUE,term_type_gg=FALSE)Each cluster has it’s own individual gprofiler plot, these are found in ‘TS_results/gprofiler_results/figures’. The gost plot for the most variable cluster (C5) is shown below. These interactive plots show the results of various databases when queried with a list of genes. More information concerning these plots and their various datasources can be found at the following link: https://biit.cs.ut.ee/gprofiler/gost Below is a non-interactive version of the plot, interactive versions can be obtained by setting the return_interactive’ parameter to the above wrapper function to `TRUE’. In the interactive version you can hover over each dot to obtain the relevan information of that specific dot.
In addition to the standard gprofiler plot, the TimeSeries pipeline creates Multi-Dimensional Scaling (MDS) plots. These plots illustrate a custom selected ontology defined by the ‘my_ont_gpro’ parameter. The first MDS plots shows all the found terms of the specified ontology and distinguishes them based on the cluster(s) in which they are found. In a MDS plot, the distance between each dot represents the semantic similarity between terms(Yu et al. 2010; Wang et al. 2007). This can be loosely defined as the ‘closeness’ between terms. Semantic similarity takes into account many factors, such as the content of the terms (genes which belong to it), it’s associations to other terms, the similarity or lack there-of in function etc… In an MDS plot, the dimensions will be adjusted to fill the space with all the terms, therefor there is no set metric to measure the similarity. The purpose of the MDS plot is moreso to help visualize different groupings (or clusters) of relevant terms. This plot can be seen by entering . Due to the large number of possible hits in a standard term based MDS, an alternate version was created. The second version of the MDS plot provides a nearest ancestor clustering approach. All terms found are brought up to their nearest common ancestor. Since these databases, GO ontology in particular, have a tree-like hierarchy, we are able to find common ancestors for each term which may provide a broader view if too many individual terms exist. This approach does not distinguish based on clusters in which terms were found, meaning that terms from different clusters may be paired together. The size of each dot in this approach is relative to the number of terms sorted in that common ancestor (dot) while the color is representative of the dominant cluster in that common ancestor. For example, if an ancestor has 4 terms within it, and 3 of those terms are found in cluster 1 (C1), the dot will carry the color associated to C1. An interactive version can also be obtained by setting the ‘term_type_gg’ parameter to FALSE
## NULLGprofiler results – custom
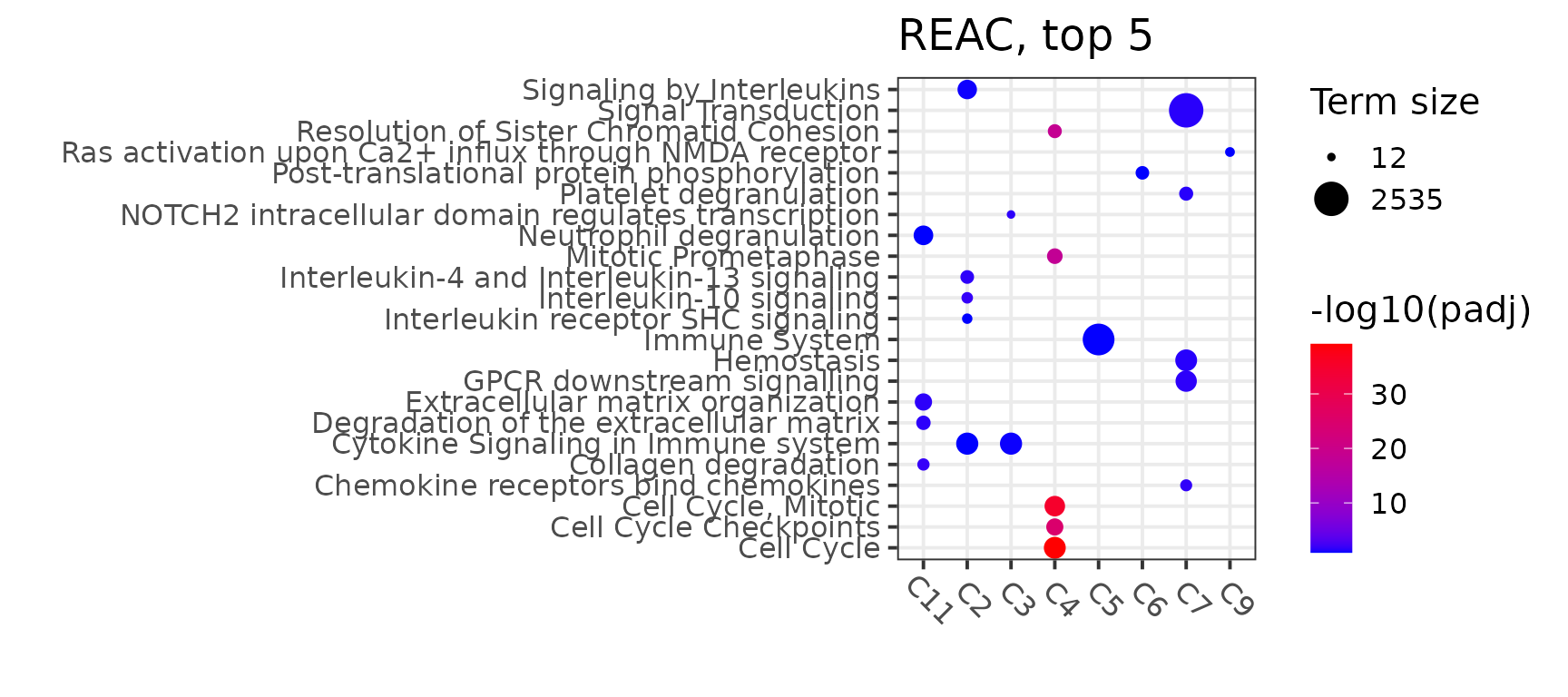
Dotplots were designed to illustrate the top n term results for any single ontology. In the below code chunk three different ontologies are demonstrated, GO:BP (biological processes), REAC (REACTOME) (Jassal et al. 2020) and KEGG(Kanehisa et al. 2017). The ‘target_top’ parameter defines the number of terms (from most significant to least) per cluster that will be shown on the dotplot.
All terms shown are considered to be significant, the ‘top’ aspect reflects significance based on the adjusted p value. The adjusted p value is negatively log transformed in order to offer a better visualization, with most significant being in red and less significant (but still statistically significant) in blue.
target_top=5
select_ontology<-'REAC'
gpro_REAC_dotplot<-GO_dotplot_wrapper(TS_object,file_loc=NULL,target_ontology=select_ontology,top_n=target_top,return_plot = TRUE)Illustrated below is the dotplot for the REACTOME pathway.
Ancestor query plots
Ancestor query plots were designed to query results relating to specific GOs.
This plot searches for children of the queried term IDs. Pathways, such as GO pathways are hierarchically organized, so a single ID will be associated to other IDs. For example, the ‘immune system process (GO:0002376)’ contains several ‘children’, each of these children is likely to have children of their own and so on. If we use the ID for ‘immune system process’ this plot will find all children grand-children great-grand children etc… of ‘immune system process’. It will then split the children based on the PART cluster in which they were found, these results are illustrated in dotplot format. This is accomplished via the GO.db package(Carlson 2021)
Several websites exist to search for GO ancestors of interest, ‘AMIGO2’ is one and ‘quickGO’ is another.
A word of caution with this type of plot. It will always link terms to the most upstream ancestor, so if the query contains two term IDs which are related to each other, the plot will illustrate all results as belonging to the term ID which is the most upstream (oldest/ancestor). Each ancestor queried for will be illustrated in different colors on the dotplot.
#Dotplot for terms relating to specific ancestors
#Check if analysis is required, if not, set to null or empty
if(length(target_ancestors)==0){
ancestor_plots<-list()
ancestor_plots[['MDS']]<-NULL
GOs_ancestors_clust<-data.frame(NULL)
}else{
GOs_ancestors_clust<-find_relation_to_ancestors(target_ancestors,GO_clusters,ontology = ancestor_ontology)
ancestor_plots<-wrapper_ancestor_curation_plots(GOs_ancestors_clust,sem_dta,return_plot=TRUE,target_dir=NULL,term_type_gg=FALSE)
}Two formats are generated for the ancestor plot. The first is a MDS plot. The second is a dotplot version. If more than one term was found to be associated to ancestors, the MDS plot will be created and can be seen below, otherwise only the dotplot will be created. The dotplot will not be created if no terms were found. The files for both of these plots can be found in ‘TS_results/ancestor_plots’. In the MDS and dotplot alike, the color of each term represents the ancestor to which they have been associated and the size is proportional to the -log transformed adjusted p-value. In the MDS plot, the PART clusters in which these terms are found can be seen by hovering over each dot, in the dotplot version, this information is made available on the x axis while the y axis represents the terms. For the MDS plot, an interactive version can also be obtained by setting the `term_type_gg’ parameter to FALSE.
A interactive table is also generated in order to better navigate the results in the event of a large number of terms found for many different ancestors. The csv version of this data can be found in ‘TS_results/ancestor_plots’.
GO:0002252
Ancestor name: immune effector process
| term ID | term name | PART cluster |
|---|---|---|
| GO:0001909 | leukocyte mediated cytotoxicity | C5 |
| GO:0001910 | regulation of leukocyte mediated cytotoxicity | C5 |
| GO:0001912 | positive regulation of leukocyte mediated cytotoxicity | C5 |
| GO:0002228 | natural killer cell mediated immunity | C5 |
| GO:0002252 | immune effector process | C5 |
| GO:0002263 | cell activation involved in immune response | C5 |
| GO:0002275 | myeloid cell activation involved in immune response | C5 |
| GO:0002366 | leukocyte activation involved in immune response | C5 |
| GO:0002443 | leukocyte mediated immunity | C2 |
| GO:0002443 | leukocyte mediated immunity | C5 |
| GO:0002449 | lymphocyte mediated immunity | C2 |
| GO:0002449 | lymphocyte mediated immunity | C5 |
| GO:0002456 | T cell mediated immunity | C2 |
| GO:0002697 | regulation of immune effector process | C5 |
| GO:0002697 | regulation of immune effector process | C2 |
| GO:0002699 | positive regulation of immune effector process | C5 |
| GO:0002703 | regulation of leukocyte mediated immunity | C5 |
| GO:0002703 | regulation of leukocyte mediated immunity | C2 |
| GO:0002705 | positive regulation of leukocyte mediated immunity | C5 |
| GO:0002706 | regulation of lymphocyte mediated immunity | C5 |
| GO:0002708 | positive regulation of lymphocyte mediated immunity | C5 |
| GO:0002715 | regulation of natural killer cell mediated immunity | C5 |
| GO:0002717 | positive regulation of natural killer cell mediated immunity | C5 |
| GO:0042267 | natural killer cell mediated cytotoxicity | C5 |
| GO:0042269 | regulation of natural killer cell mediated cytotoxicity | C5 |
| GO:0045954 | positive regulation of natural killer cell mediated cytotoxicity | C5 |
GO:0002253
Ancestor name: activation of immune response
| term ID | term name | PART cluster |
|---|---|---|
| GO:0002220 | innate immune response activating cell surface receptor signaling pathway | C5 |
| GO:0002223 | stimulatory C-type lectin receptor signaling pathway | C5 |
GO:0002682
Ancestor name: regulation of immune system process
| term ID | term name | PART cluster |
|---|---|---|
| GO:0002682 | regulation of immune system process | C11 |
| GO:0002682 | regulation of immune system process | C5 |
| GO:0002683 | negative regulation of immune system process | C5 |
| GO:0002684 | positive regulation of immune system process | C11 |
| GO:0002684 | positive regulation of immune system process | C5 |
| GO:0002685 | regulation of leukocyte migration | C11 |
| GO:0002694 | regulation of leukocyte activation | C5 |
| GO:0002819 | regulation of adaptive immune response | C2 |
| GO:0002822 | regulation of adaptive immune response based on somatic recombination of immune receptors built from immunoglobulin superfamily domains | C2 |
| GO:0045088 | regulation of innate immune response | C5 |
| GO:0045089 | positive regulation of innate immune response | C5 |
| GO:0050776 | regulation of immune response | C5 |
| GO:0050778 | positive regulation of immune response | C5 |
| GO:0050863 | regulation of T cell activation | C5 |
| GO:0051249 | regulation of lymphocyte activation | C5 |
GO:0006955
Ancestor name: immune response
| term ID | term name | PART cluster |
|---|---|---|
| GO:0002250 | adaptive immune response | C5 |
| GO:0002460 | adaptive immune response based on somatic recombination of immune receptors built from immunoglobulin superfamily domains | C2 |
| GO:0006955 | immune response | C11 |
| GO:0006955 | immune response | C5 |
| GO:0006955 | immune response | C2 |
| GO:0006955 | immune response | C3 |
| GO:0042092 | type 2 immune response | C2 |
| GO:0045087 | innate immune response | C5 |
Session information
## R version 4.5.0 (2025-04-11)
## Platform: x86_64-pc-linux-gnu
## Running under: Pop!_OS 22.04 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## time zone: Europe/Oslo
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] org.Hs.eg.db_3.21.0 AnnotationDbi_1.70.0
## [3] ggplot2_3.5.2 TimeSeriesAnalysis_01.03.01
## [5] BiocFileCache_2.16.0 dbplyr_2.5.0
## [7] SummarizedExperiment_1.38.1 Biobase_2.68.0
## [9] GenomicRanges_1.60.0 GenomeInfoDb_1.44.0
## [11] IRanges_2.42.0 S4Vectors_0.46.0
## [13] BiocGenerics_0.54.0 generics_0.1.4
## [15] MatrixGenerics_1.20.0 matrixStats_1.5.0
## [17] knitr_1.50
##
## loaded via a namespace (and not attached):
## [1] RColorBrewer_1.1-3 rstudioapi_0.17.1 jsonlite_2.0.0
## [4] shape_1.4.6.1 tximport_1.36.1 magrittr_2.0.3
## [7] farver_2.1.2 rmarkdown_2.29 GlobalOptions_0.1.2
## [10] fs_1.6.6 ragg_1.4.0 vctrs_0.6.5
## [13] memoise_2.0.1 htmltools_0.5.8.1 S4Arrays_1.8.1
## [16] dynamicTreeCut_1.63-1 curl_6.4.0 tictoc_1.2.1
## [19] SparseArray_1.8.0 sass_0.4.10 bslib_0.9.0
## [22] htmlwidgets_1.6.4 desc_1.4.3 plyr_1.8.9
## [25] plotly_4.11.0 cachem_1.1.0 tximportData_1.36.0
## [28] mime_0.13 lifecycle_1.0.4 iterators_1.0.14
## [31] pkgconfig_2.0.3 Matrix_1.7-3 R6_2.6.1
## [34] fastmap_1.2.0 GenomeInfoDbData_1.2.14 shiny_1.11.1
## [37] clue_0.3-66 digest_0.6.37 colorspace_2.1-1
## [40] DESeq2_1.48.1 textshaping_1.0.1 crosstalk_1.2.1
## [43] RSQLite_2.4.1 filelock_1.0.3 labeling_0.4.3
## [46] org.Mm.eg.db_3.21.0 httr_1.4.7 abind_1.4-8
## [49] mgcv_1.9-3 compiler_4.5.0 bit64_4.6.0-1
## [52] withr_3.0.2 doParallel_1.0.17 BiocParallel_1.42.1
## [55] DBI_1.2.3 R.utils_2.13.0 DelayedArray_0.34.1
## [58] rjson_0.2.23 tools_4.5.0 httpuv_1.6.16
## [61] R.oo_1.27.1 glue_1.8.0 promises_1.3.3
## [64] nlme_3.1-168 GOSemSim_2.34.0 grid_4.5.0
## [67] cluster_2.1.8.1 reshape2_1.4.4 gtable_0.3.6
## [70] tzdb_0.5.0 R.methodsS3_1.8.2 tidyr_1.3.1
## [73] data.table_1.17.8 hms_1.1.3 XVector_0.48.0
## [76] ggrepel_0.9.6 foreach_1.5.2 pillar_1.11.0
## [79] stringr_1.5.1 yulab.utils_0.2.0 limma_3.64.1
## [82] later_1.4.2 circlize_0.4.16 splines_4.5.0
## [85] dplyr_1.1.4 lattice_0.22-7 bit_4.6.0
## [88] tidyselect_1.2.1 GO.db_3.21.0 ComplexHeatmap_2.24.1
## [91] locfit_1.5-9.12 Biostrings_2.76.0 xfun_0.52
## [94] statmod_1.5.0 stringi_1.8.7 UCSC.utils_1.4.0
## [97] lazyeval_0.2.2 yaml_2.3.10 evaluate_1.0.4
## [100] codetools_0.2-20 tibble_3.3.0 BiocManager_1.30.26
## [103] cli_3.6.5 org.Ce.eg.db_3.21.0 xtable_1.8-4
## [106] systemfonts_1.2.3 jquerylib_0.1.4 Rcpp_1.1.0
## [109] gprofiler2_0.2.3 png_0.1-8 parallel_4.5.0
## [112] pkgdown_2.1.3 readr_2.1.5 blob_1.2.4
## [115] viridisLite_0.4.2 scales_1.4.0 purrr_1.1.0
## [118] crayon_1.5.3 GetoptLong_1.0.5 rlang_1.1.6
## [121] KEGGREST_1.48.1